Calculated Performance
ZenPacks.zenoss.CalculatedPerformance
The Calculated Performance ZenPack provides a few capabilities for creating derived datapoints. A derived datapoint's value is determined based on the values of other datapoints or attributes, as opposed to being collected directly from a target device or component. There are two different types of derived datapoint provided: Calculated Performance and Datapoint Aggregator. Both of these types are collected within the zenpython daemon provided by PythonCollector, so no new daemons are required.
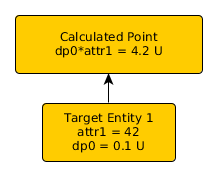
Calculated Performance datapoints are functionally the same as in v1.x. By configuring a Python expression, you can combine any datapoints or model attributes from the target device or component. The capabilities of the Python expression have been expanded in v2.0.
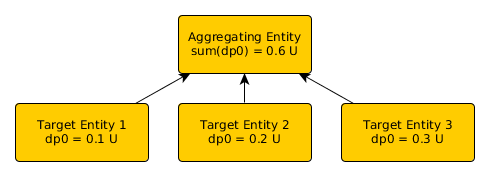
Datapoint Aggregator datapoints are a new capability in v2.0. They perform a point-in-time aggregation of any other datapoint on a set of target elements. The target elements in question can be any elements in the Zenoss system that have datapoints associated with them. This is not limited by type, Device Class, or containing device, though it is limited to elements collected on the same physical collector as the aggregating element. An aggregation can be any n-ary commutative mathematical operation, such as sum, maximum, or standard deviation. Most aggregations give results in the same units as the input.
Open Source
This ZenPack is developed and supported by Zenoss Inc. Contact Zenoss to request more information regarding this or any other ZenPacks. Click here to view all available Zenoss Open Source ZenPacks.
Releases
Version 2.5.1 - Download
- Released: 2018-04-30
- Requires: PythonCollector ZenPack (>=1.9)
- Compatible with Zenoss 4.2.5 - 6.1.2
Version 2.5.0 - Download
- Released: 2017-10-27
- Requires: PythonCollector ZenPack (>=1.9)
- Compatible with Zenoss 4.2.5 - 5.3
Version 2.4.2 - Download
- Released: 2017-10-17
- Requires: PythonCollector ZenPack (>=1.9)
- Compatible with Zenoss 4.2.5 - 5.3
Version 2.4.0 - Download
- Released: 2017-03-31
- Requires: PythonCollector ZenPack (>=1.9)
- Compatible with Zenoss 4.2 - 5.2
Version 2.3.2 - Download
- Released: 2017-03-17
- Requires: PythonCollector ZenPack (>=1.3.0)
- Compatible with Zenoss 4.2 - 5.2
Version 2.3.1 - Download
- Released: 2017-03-04
- Requires: PythonCollector ZenPack (>=1.3.0)
- Compatible with Zenoss 4.2 - 5.2
Version 2.2.1 - Download
- Released: 2016-08-02
- Requires: PythonCollector ZenPack (>=1.3.0)
- Compatible with Zenoss 4.2 - 5.1
Version 2.1.0 - Download
- Released: 2015-09-16
- Requires: PythonCollector ZenPack (>=1.3.0)
- Compatible with Zenoss 4.2 - 5.0
Version 2.0.4 - Download
- Released: 2014-10-08
- Requires: PythonCollector ZenPack (>=1.3.0)
- Compatible with Zenoss 4.2
Version 1.0.9 - Download
- Released: 2014-03-18
- No additional requirements.
- Compatible with Zenoss 3.1 - 4.2
Usage
Calculated Performance Datasource
A Calculated Performance datasource contains a Python expression whose
result will be stored as the value of the single datapoint. The
expression can reference any other datapoint or model attribute on the
device or component. For example, the expression
(hw.totalMemory – memAvailReal) / hw.totalMemory uses the totalMemory
attribute modeled from the device and the datapoint memAvailReal to
calculate a percentage used. Dotted-name model attributes can reference
functions or relationships as long as they take no arguments.
The expression can reference datapoints using any of the following syntaxes. Replace dsname with the name of your datasource and dpname with the name of your datapoint.
dpname: This option is the simplest if you know that your datapoint name is unique for the device or component to which it's bound, and the datapoint name is a valid Python variable name (i.e. it contains no hyphens.)dsname_dpname: This option should be used if there's a chance that your datapoint name is not unique for the device or component. Using the datasource name's then an underscore as a prefix guarantees uniqueness. This option requires that both the datasource and datapoint name be valid Python variables names. Support for this syntax was added in version 1.0.7.datapoint['dpname']: This option can be used if the datapoint's name is not a valid Python variable name and the datapoint is unique for the device or component to which it's bound. Support for this syntax was added in version 2.0.3.datapoint['dsname_dpname']: This is the most verbose, but safest option. It can be used when the datapoint name is not unique, and either the datasource or datapoint name is not a valid Python variables name. Support for this syntax was added in version 2.0.3.
If there are model attributes and datapoints that have a name conflict, the datapoint's value will be used. To disambiguate, you can use here.attribute to specify a model attribute, and the dsname_dpname name to specify a datapoint.
In v2.0, the capabilities of the expression have been expanded. Any eval-able Python code can be used, including control structures and any built-in functions, as long as it returns a single numeric value. This means that any Python keyword and any Python builtin are reserved words that cannot be used as attribute or datapoint names. If a model attribute or datapoint has a name conflict with a reserved identifier, the here.attribute or dsname_dpname syntax will resolve the issue.
In addition, the expression has access to a few provided utility functions:
avg(dpList): Computes the average value of a list of items, excluding any None values.pct(numeratorList, denominatorList): Computes a percentage of sums of the numerator list and the denominator list. None values are assumed to be zero, and if the denominator is zero the returned value is zero.
Datapoint Aggregator Datasource
A Datapoint Aggregator datasource is a datasource like any other: it resides in a template, which will be bound to a device or component that we will attempt to collect against. The aggregating datasource has two important pieces of configuration: the target elements to get data from, and the target datapoint on those elements.
The elements to collect from are controlled by the configured Target Method name. This can be any method or relationship present on the element type to which the template will be bound, and must require no arguments. This method must return an iterable of all elements against which we will collect. For example, for an aggregate datasource on a device, we could collect from all of its components by setting this field to getMonitoredComponents or from all of its interfaces by using os.interfaces. By default, the method is getElements, which is expected to be used on a custom ElementPool component. See: Implementing a Custom ElementPool Component.
The datapoint to collect from each element is specified by the Datasource, Datapoint, and RRA fields. As expected, this will collect the value from dsname_dpname:RRA on each target element before aggregating the set of values.
A datapoint on a Datapoint Aggregator type datasource provides the configuration of the aggregation operation to perform on the set of collected values. Multiple such datapoints can be configured on a single datasource to perform several aggregations on the same set of data. The 'Operation' field must be one of the available operations provided by the ZenPack. Some operations may take additional arguments, which should be a string of comma-separated values in the 'Arguments' field.
Available Aggregation Operations
The following aggregation operations are available (aliases included). Operations that result in different units than those submitted are noted.
- count: The number of elements collected. Not unit-consistent.
- sum: The sum of all elements collected.
- max: The maximum of all elements collected.
- min: The minimum of all elements collected.
- amean (avg): The arithmetic mean or average of all elements collected.
- median: The median of all elements collected.
- stddev (std): The standard deviation of all elements collected.
- var: The variance of all elements collected. Not unit-consistent.
- mad: The median absolute deviation of all elements collected.
- percentile: Takes an additional argument n (0-100). Returns the nth percentile value from the set of target datapoints.
Thresholding on Aggregate Datapoints: Additional Event Detail
When a MinMax threshold is violated on an aggregate datapoint, an additional event detail is added to the generated event. The violator detail of the event will contain a set of (uid, value) tuples for each target element whose value is above the threshold. For example, if the median operation is applied to [3,3,5,9,11] and has a maximum threshold of 4, the elements corresponding to the 5, 9, and 11 values would appear in the violator detail.
The value given in the violator tuple will correspond to the aggregate operation requested: the std and mad operations will provide each element's deviation as its corresponding value, and the var operation will provide the square of each element's deviation. All other aggregations will use the value of the target datapoint as collected.
Best Practices for Derived Datapoints: Using Topological Sort
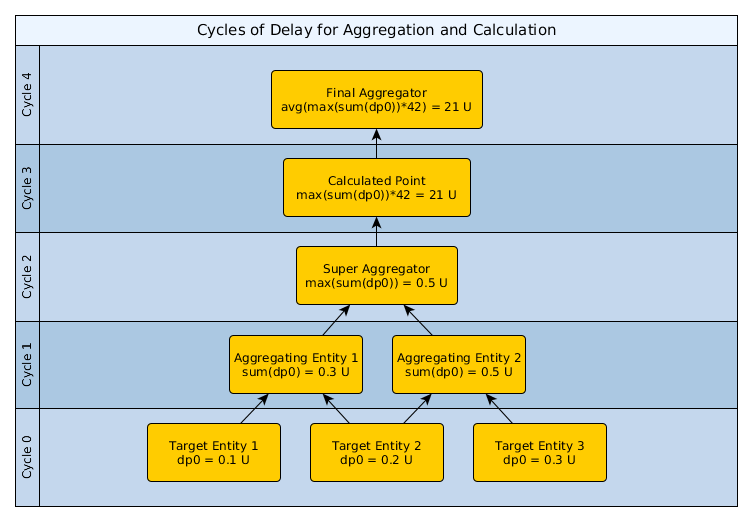
As mentioned above, both Calculated Performance and Datapoint Aggregator datasources incur a 1-collection cycle delay when collecting. This problem compounds when both are in play. Each time you calculate or aggregate a datapoint, a 1-cycle delay is added. In this example, some aggregations are performed, then a calculation, then a final aggregation. Each step incurs a 1-cycle delay, resulting in data that is 4 cycles old by the time the final aggregation is stored.
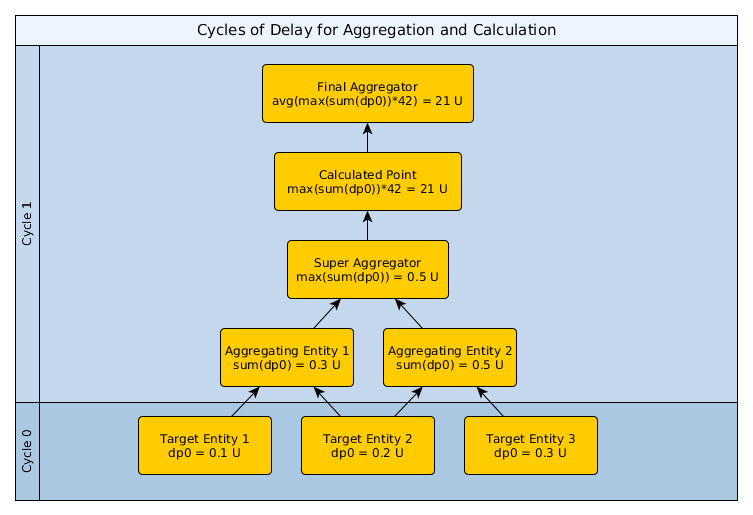
However, not all compound datapoints necessarily incur a delay. If the derived datapoints for the Final Aggregator, Calculated Point, Super Aggregator, and both Aggregating Entities are set to the same cycle time, and all of these datasources are within a single device's context (i.e., the device itself or a component of that device), we will perform a topological sort on the datapoint dependency graph to attempt to collect them so that all three values are available within one collection cycle. This sorting requires that there be no cyclic dependencies between datapoints.
Implementing a Custom ElementPool Component
There are many scenarios for using an aggregate datapoint where it makes no sense to put the aggregate datapoint on an existing device or component. For example, an aggregate datapoint may want to calculate across disparate devices and components. For this situation, we provide a generic ElementPool component. The base ElementPool stores its members as a list of UUIDs of device/components to target, and implements the getElements() method that will return the appropriate list.
To implement your own specific type of component with pool functionality, inherit from ElementPool and implement the getMembers() method as desired. Your component need not use the internal member list, or may store other values in the list, as long as the getMembers() method returns the correct items. Then, configure your aggregate datapoints to target the getMembers function (this is the default).
You must create these components at modeling time like any other component. Then the configured datapoints will be collected.
class RandomContentsElementPool(ElementPool):
portal_type = meta_type = 'RandomContentsElementPool'
def getElements(self):
return [x for x in self.device().getMonitoredComponents() if random.random() > 0.314159]
Caveats
All derived datapoints rely on reading previously collected target datapoints from the performance data store. As such, the calculation of the derived value will be delayed by as much as an entire collection cycle. In general, derived datapoints should be considered to incur a 1-cycle delay for each aggregation or calculation step. In practice, we can often compute an entire tree of aggregation and calculation steps in the same collection cycle. See: Best Practices for Derived Datapoints: Using Topological Sort.
Derived datapoints are only based on the most recent available data from target datapoints. This is limited to data up to 5*cycleTime seconds in the past. If a target datapoint does not exist on the target element, or has not been collected in the recent past, that element will be excluded from the calculation. This may mean that fewer datapoints than desired are used in the calculation (for aggregate datapoints), or that the overall result cannot be calculated at all. An event will be sent when this occurs.
Zenoss 4 Note
Performance data is stored locally on the collector. So only data from devices and components on the same collector can be aggregated. This is not a limitation in Zenoss 5, Zenoss 6, or Zenoss Cloud.
Auto Adjustment of the Collection Intervals
By default, Zenoss tries to auto adjust the collection intervals for both Calculated Performance and Datapoint Aggregator datasources to show aligned data intervals on the utilization graphs. It determines basis collection interval of the target datapoints and uses the interval for the aggregated/calculated datasources. In case of multiple basis datapoints with different collection intervals, the shortest interval will be used.
If you want to disable this feature, you have uncheck the "Use Basis Interval" flare for your aggregated/calculated datasources. The "Use Basis Interval" property can be found on the aggregated/calculated datasource's configuration menu. When the "Use Basis Interval" is checked, the Minimum and Maximum Interval properties will be used to set limits of the basis interval. For instance, when the basis interval equals to 40 seconds and the Minimum Interval value is 60 seconds, the Minimum Interval will be used as the collection interval, the same rule is applicable to the Maximum Interval property. Minimum Interval cannot be less than 1 second.
Zenoss 4 Note
The auto adjustment of the collection intervals works only on Zenoss 5.
Changes
2.5.1
- Fix missing datapoints on UCS Capacity graphs. (ZPS-3282)
- Add additional debug logging. (ZPS-3404)
- Tested with Resource Manager 4.2.5 RPS 743, 5.3.3, 6.1.2
2.5.0
- Add "Extra Contexts" support to Calculated Performance datasource.
2.4.2
- Use configured cycletime of basis datasources for "Use Basis Interval". (ZPS-2077)
2.4.0
- Add "Use Basis Interval" option to all datasource types. (ZPS-1134)
2.3.2
- Support new contextMetric capability in Zenoss 5.2.3. (ZEN-27010)
2.3.1 - 2017-03-04
- Clarify event when aggregation operation is blank or invalid. (ZPS-71)
- Change default aggregation operation from blank to "sum". (ZPS-71)
2.3.0 - 2016-11-17
- Reduce impact on zauth with better cookie usage. (ZEN-24527)
2.2.1 - 2016-08-02
- Added zDatasourceDebugLogging property to control debug logging. (ZEN-22318)
- Reduce install/upgrade time. (ZEN-22318)
- Add "Rate?" option for both datasource types. (ZEN-22972)
- Improve performance with HTTP connection pooling in Zenoss 5. (ZEN-23868)
2.2.0 - 2015-11-11
- Add impact from members to ElementPool. (ZEN-19846)
- Fix bogus calculations when basis counters reset. (ZEN-20694)
2.1.0 - 2015-09-16
- Improve performance by using wildcard metric queries.
- Fix "CookieAgent" error when used with Zenoss 4.
- Fix median operation on aggregating datapoints.
2.0.5 - 2015-02-22
- Use a requests Session and cache at the class level to reduce authentication load. (ZEN-15835)
2.0.4 - 2014-10-08
- Descriptions added to aggregating datasources.
- Add zDatasourceDebugLogging property to debug calculated/aggregated datasources on a single device.
- Some defensive improvements with nice error messages.
2.0.3 - 2014-09-11
- Add new datapoint['dpname'] expression syntax for hyphenated datapoint names. (ZEN-12489)
2.0.2 - 2014-07-14
- Fix ZEN-11832: Hub will now at least send 'targets' and 'expression' when things are wrong. Collection method now will allow some missing things from the params dict.
- Fix misc issues causing NaNs to show up in graphs.
2.0.1 - 2014-05-20
- Ability to concatenate iterables in expressions and methods
- New 'madmax' aggregate operation, for Median Absolute Deviation calculations on values restricted to a maximum.
- Fix ZEN-11235: zen.CalculatingPlugin has many failures of unsupported operand type
- Fix ZEN-11278: Builtins misrecognized in expressions
- Fix ZEN-11428: CalculatedPerformance 2.0.0 error starting daemons on v411
- Fix ZEN-11432: exceptions.UnboundLocalError in zenpython.log
- Fix ZEN-11492: Missing some datasource properties
- Fix ZEN-11580: CalculatedPerformance 2.0.0 has Dependency on PythonCollector>1.3.0
2.0.0 - 2014-04-07
- Add aggregating datapoint capabilities.
- Add ElementPool components for aggregations.
- Rewrite collection to use PythonCollector.
1.0.9 - 2014-03-18
- Support device properties in expressions. (ZEN-10648)
- Prevent failure when one expression contains an error. (ZEN-10649)
1.0.8 - 2014-01-06
- Stop defaulting missing datapoints to 0. (ZEN-9610)
1.0.7 - 2013-07-15
- Allow short name (dpname) or long name (dsname_dpname) in calculations.
1.0.6 - 2013-06-19
- Remove broken 'Test' button from datasource dialog.
1.0.5 - 2013-04-0388
- Initial open source release.